Getting IO right
We
recently embarked on a new project in a subject that we were familiar with
(network configuration at scale) and that we have implemented previously in a
different context in Java. Our new project challenged us to take a new look at
the subject and to come up with an implementation that further improves
performance, has a smaller footprint and adds new functionality. We finally
implemented the project in C++.
In the following posts we will share our experiences on that journey. We would love to hear from you. You can follow the progress of our journey here: https://github.com/facebookincubator/magma/tree/master/devmand/gateway

Getting IO right
The
project that we are working on reads data from many different networking
devices. We establish an SSH session with each device and crawl its
configuration and stats by issuing a multitude of commands. We also provide the
capability to translate the information we collect and send to standards based
data models (Openconfig YANG). We also offer the ability to write configuration
to devices.
Having
open connections to many devices at the same time poses a design challenge
similar to that of web servers. A low overhead per open SSH session, being able
to quickly respond to the activity on a particular device and process incoming
data are all requirements that need to be fulfilled.
Our
first (prototype) C++ implementation for handling connections and data was
using a fixed size thread-pool to handle incoming
traffic and periodic polling of data using the ssh_channel_read_timeout call. Somewhat naive
approach, but for getting something up and running quickly and verifying our
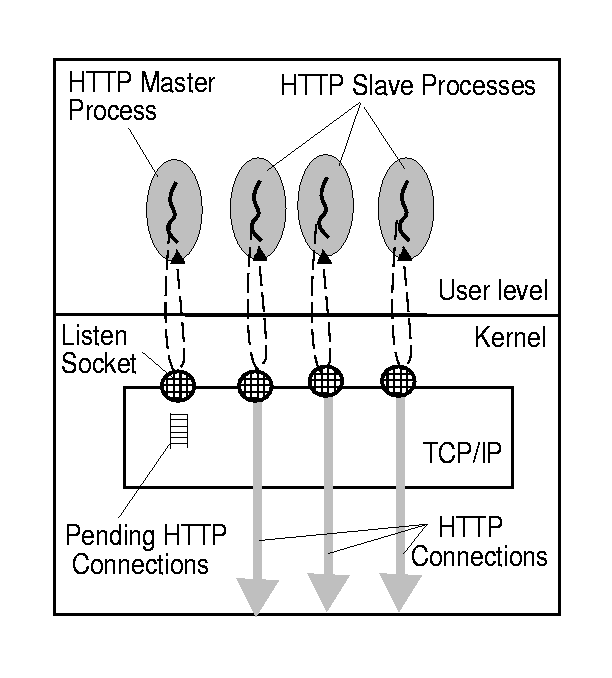
assumptions it was sufficient. This is similar to Apache’s one-process-per-connection model where
a master process pre-forks slave processes which handle the incoming traffic
(except that we had threads that don’t suffer from disadvantages like expensive fork()-s etc.).
As we
added more logic (i.e. device commands to execute via SSH) and more devices the
“temporary” solution became a performance bottleneck. At some point it took
over a minute to read all the data we were collecting from a single device. Of
course, the most reasonable next step was to tweak the size of the thread-pool,
change timeouts and do other micro-optimizations. It soon turned out this was a
dead-end and we needed to rehaul this part of the system. Before
we actually started to rewrite this subsystem, we had decided to pin down any
established design patterns in order to get the most bang for the buck in terms
of networking IO.
We
looked into popular projects to draw inspiration from (i.e. “borrow” their
design :-). Most notably we looked into NodeJS which is a single thread application written in C++ that
achieves high throughput.
NodeJS
uses only a single thread to receive connections from users and treats these
requests as events. The basic idea behind the NodeJS “event-loop” can be seen
on this diagram.
We also
turned our attention to Nginx as
this is the most popular web server today and claims it can “handle millions of
simultaneous requests and scales very well”. The Nginx team identified
their greatest scaling “enemy” – blocking. The core of
Nginx is a readiness notification handler that receives information about
connection events from the kernel and then processes them one by one. The Nginx
core uses a task queue and a small number of consumer threads in order to
offload long running tasks somewhere else so they do not slow down the main
loop. This pattern fits our problem pretty nicely as we have low volume data
coming from the SSH which needs to be parsed and processed (e.g. regexp
evaluation, string manipulations and data handling).
From
these real-world examples and also after reading the famous c10k article we came up with the following principles:
· Don’t
use any blocking or synchronous calls (if possible),
· use the
network readiness notifications via the kernel API,
· one
reader can handle data reads for many devices,
· any
subsequent processing or data manipulation needs to happen outside of the
reader thread’s scope,
· solution
needs to work on different *nix systems.
Next,
we needed to pick the right kernel API for data notifications. As epoll being I/O notification
standard and having the best performance this was a no-brainer.
Unfortunately not every system supports epoll, so we needed to have some
fallback mechanism which would always pick the best kernel API available on the
particular system. There are multiple libraries that can be used for this purpose,
most widely used are libuv (created and used by
NodeJS), libev and libevent. Long story short, we decided to use libevent. The performance
benchmarks are similar between libuv, libev and
libevent (libevent falls slightly behind in certain situations) but libevent
has a large active community, mailing list, is well documented and its
programming model fits nicely with the design we intended to have. We ended up
using a pattern that has a data queue where we push incoming SSH output
snippets and a second queue where we schedule the processing.
We
rewrote the original code using the pattern above. You register a libevent callback that is triggered once data from SSH is available. The
callback pushes data into the queue and adds a task into the processing
queue. In the end we got the performance and responsiveness that we were
looking for – going down from minutes to milliseconds.



{kind=link}
{kind=link}
Comments
Post a Comment